この記事で分かること
複数の階層を「>」などで結合した文字列から、末尾の階層だけを抽出する方法を紹介します。
例) 株式会社S>T事業本部>U事業部>V部>W課 → V部>W課
DAXの SUBSTITUTE関数 を中心に、FIND・LEN・MID関数を組み合わせて解決します。
実務では、組織名や住所、\で結合したフォルダ階層などの「長い文字列を簡潔に表示したいとき」に役立ちます。
課題:右から区切り位置を指定して抽出したいケース
会社や工場の組織名は、次のように階層を「>」でつないで表記することがあります。
例) 会社名>部門名>課名

ただし、上位の階層は全員同じため、表示すると冗長になりがちです。
見やすくするためには、下から2番目以降の階層だけを取り出すとよいでしょう。
今回の課題は、「>」で区切られた文字列から下から2番目以降の階層を抽出することに定めます。
DAXで解決可能ですが、複数の関数を組み合わせる必要があるため少し複雑です。
このあと「答え」で関数式を示し、続いて「解説」で導出の流れを説明します。
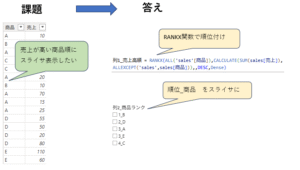
答え:ポイントはSUBSTITUTE関数
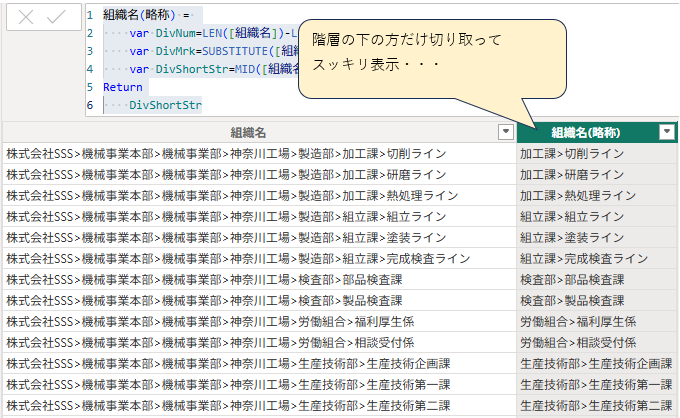
組織名(略称) =
//区切り文字 “>” の出現回数を数える
VAR DivNum = LEN([組織名]) – LEN(SUBSTITUTE([組織名], “>”, “”))
//右から2番目の区切り文字を「★」に置換する
VAR DivMrk = SUBSTITUTE([組織名], “>”, “★”, DivNum – 1)
//「★」以降の文字列を切り出す
VAR DivShortStr = MID([組織名], FIND(“★”, DivMrk, 1) + 1, LEN(DivMrk))
RETURN
DivShortStr
[組織名] は正式な組織名(省略なし)を入力した列です。
数式を分かりやすくするために 3つの変数(DivNum・DivMrk・DivShortStr) に分けています。
この仕組みを順に解説します。
解説:各DAX関数の働き
① 区切り文字の出現回数を数える(DivNum)
VAR DivNum = LEN([組織名]) – LEN(SUBSTITUTE([組織名], “>”, “”))
LEN([組織名]) → 元の文字列の文字数
LEN(SUBSTITUTE([組織名], “>”, “”)) → 区切り文字を削除した文字数
その差分 = 区切り文字の出現回数
何故、出現回数が必要?
SUBSTITUTE関数は「左から〇番目」を指定できますが「右からn番目」はできないためです。
そこで出現回数(DivNum)を使って「右から」を「左から」に変換します。
方法は次の②(DivMrk)の解説をご覧ください。
② 狙った区切り文字を「★」に置換(DivMrk)
VAR DivMrk = SUBSTITUTE([組織名], “>”, “★”, DivNum – 1)
区切り文字 “>” のうち、右から2番目を「★」に置換
「★」にしたのは、文字列中の他の文字と被らない記号にすることで、狙った区切り位置を間違えないためです。
SUBSTITUTEの第4引数は「左からn番目」を指定
今回「右から2番目」を狙うため、DivNum – 1 を指定しています
★置換後のイメージ)
株式会社S>T事業本部>U事業部>V部>W課
→ 株式会社S>T事業本部>U事業部★V部>W課
例)
右から2番目 → DivNum – (2 – 1) = DivNum – 1
右から3番目 → DivNum – (3 – 1) = DivNum – 2
右から4番目 → DivNum – (4 – 1) = DivNum – 3
この一般式を覚えておけば、任意の階層を抽出する処理に応用できます。
③ 「★」以降の文字を抽出する(DivShortStr)
VAR DivShortStr = MID([組織名], FIND(“★”, DivMrk, 1) + 1, LEN(DivMrk))
(1) FIND(“★”, DivMrk, 1) → 「★」の位置を検索
(2) +1 することで「★」の次の文字から抽出開始
(3) LEN(DivMrk) を長さに指定し、最後まで取り出す
抽出後のイメージ)
株式会社S>T事業本部>U事業部>V部★W課
→ V部>W課
まとめ
今回の課題は「区切り文字で連結された文字列から、右から2番目以降を抜き出す」方法でした。
- SUBSTITUTE関数は「左から何番目」しか指定できない
- 区切り文字の出現回数(DivNum)を使い、「右からn番目」を「左から○番目」に変換
一般式:右からn番目は「左から DivNum – (n – 1) 番目」 - FIND・MID関数と組み合わせることで、目的の部分だけを抽出できる
実務では「組織名の略称表示」や「住所の末尾抽出」、「フォルダ階層の末尾抽出」などに応用できます。
DAXの関数を組み合わせれば、一見難しい処理も分解して実装可能です。
Power BIやDAXの実務に、ぜひ役立ててみてください。


コメント