
この記事で分かること
複数の階層を「>」などで結合した文字列から、末尾の階層だけを抽出する方法を紹介します。
例) 株式会社S>T事業本部>U事業部>V部>W課 → V部>W課
SUBSTITUTE関数、FIND関数、LEN関数、MID関数の実践的な使い方
課題|右から区切り位置を指定するのはどんな時?
今回は会社組織名を短く表示するために、組織名の右の方(組織階層の下の方)だけを抽出する方法を考えます。
下の図は、とある工場内の組織名一覧です。会社名>部門名>課名といった組織階層を”>”文字で区切って繋げています。
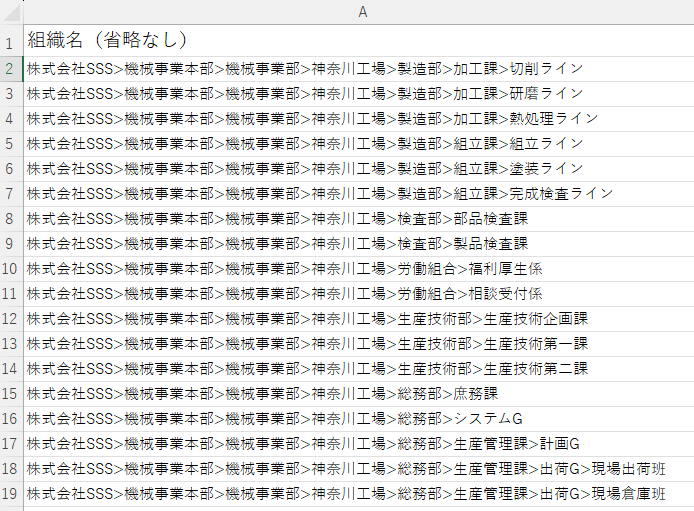
上から順に階層全てを記載しているので冗長です。同じ工場組織なので、上の方の階層はどの組織も同じ名前です。
そこで組織階層の下の方だけ、例えば下から2番目までを抜き取れば、スッキリ見やすくなると考えました。
今回の課題は”>”で区切られた会社組織名の、下から2番目の階層以降を抽出することです
狙った階層以下の所属を抜き出すことは、エクセル関数なら可能です。しかし複数の関数の組み合わせが必要なため少々難しくなります。
そこで次の「答え」では関数式を、「解説」では関数式の導出過程をご説明します。
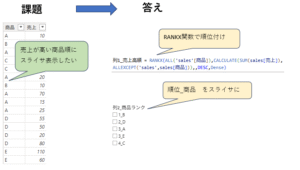
【答え】 ポイントはSUBSTITUTE関数
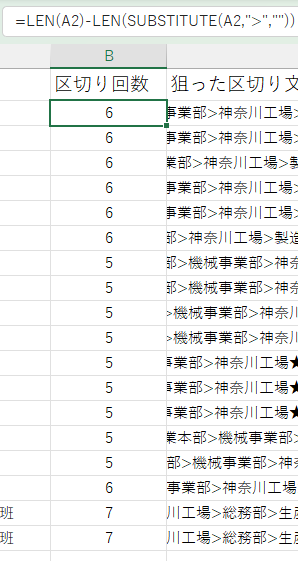
B列= LEN(A2)-LEN(SUBSTITUTE(A2,”>”,””))
C列の式= SUBSTITUTE(A2,”>”,”★”,B2-1)
D列= MID(C2,FIND(“★”,C2,1)+1,LEN(C2))
(解答は2行目の式です)
セルA列は会社組織を省略なしで入力しています。計算式は複雑なので、B列からD列の3ステップに分けています。そしてD列が最終解答です。各列の内容は次の「解説」で説明します。
【解説】 各Excel関数式の説明
まず全体の処理を大まかに説明してから、個別の処理を詳細に説明します。
全体の処理概要
最終解答のD列から導出過程を逆にたどっていきます。
D列の処理
D列では開始文字(今回は右端から2番目の区切り文字)より右側の文字列全てをMID関数で抽出します。
開始文字はC列の計算で”★”に置き換えます。
そして開始文字の位置はFIND関数で指定します。
下が処理結果です。

C列の処理
C列では「開始文字」を「他の区切り文字」とは異なる別の文字に置き換えます。それはD列のFIND関数が開始文字の位置を特定するためです。
この置き換えに使うのがSUBSTITUTE関数です。ここでは開始文字を”★”に置き換えます。
左から何番目の区切り文字を置き換えるか、はB列で計算します。
下が処理結果です。

B列の処理
B列では区切り文字の出現回数を計算します。これは区切り位置の指定を「右から」ではなく「左から」に変換するためです。
何故ならSUBSTITUTE関数は、左から何番目の区切り文字、という指定しかできないためです。
下が処理結果です。
個別の処理
上記のB列からD列の処理を詳細に説明します。
B列:区切り文字の出現回数を計算する
再掲:B列=LEN(A2)-LEN(SUBSTITUTE(A2,”>”,””))
区切り文字の出現回数は「全文字数」と「区切り文字をなくした文字数」の引き算です。
「全文字数」は右辺第一項のLEN関数で計算します。引数は文字数カウントしたい文字列、戻り値は文字数です。
「区切り文字をなくした文字数」は右辺第二項目のLEN関数とSUBSTITUTE関数の組み合わせで計算します。
LEN関数の引数に「区切り文字をなくした文字列」を渡せば、文字数が計算できます。区切り文字をなくすために、文字列中の全ての区切り文字(今回は ”>”)を、文字無し(””)に置換するのがSUBSTITUTE関数です。
即ちSUBSTITUTE関数の2番目の引数に区切り文字、3番目の引数に文字無し(””)を指定した戻り値で得られます。
C列:狙った区切り文字を★に置き換える
再掲:C列= SUBSTITUTE(A2,”>”,”★”,B2-1)
今回は右から2番目の区切り文字”>”を”★”に置き換えます。置き換え文字は”★”のような、文字列中に存在しえない特殊な文字を指定して下さい。
区切り文字の置き換えに使うのはSUBSTITUTE関数です。そしてSUBSTITUTE関数は左から何番目の区切り文字を置き換えるか、を指定できます。
今回指定する「右からn番目の区切り文字」は、左から数えると「B列で求めた出現回数」-(n-1)です。これをSUBSTITUTE関数の4番目の引数に指定します。
D列:狙った区切り文字より右の文字だけ抽出する
再掲:D列= MID(C2,FIND(“★”,C2,1)+1,LEN(C2))
ここでは上述のC列の式で”★”に置換した開始文字から右側の文字列を抽出します。
“★”置換した文字位置はFIND関数で探します。FIND関数は探したい文字が左から何番目にあるかを整数で返します。
FIND関数の1番目の引数に「探したい文字」、2番目の引数に「探したい文字を含む文字列」、3番目の引数に「左から数えた開始位置」を指定すれば、戻り値は「探したい文字」の位置です。
なお、戻り値の「文字の位置」は3番目の引数「開始位置」から左に向かって数えて、探したい文字が何番目に現れたかを返します。
“★”置換した文字位置から右側の文字列はMID関数で抽出します。
MID関数の2番目の引数は抽出開始位置です。ここでは先ほどFIND関数で計算した”★”文字の位置+1を指定します。3番目の引数は抽出開始位置から右に数えて抽出したい文字数です。抽出したい文字数はLEN関数で全文字数を指定しました。文字列の最後まで抽出するので、実際より多めに文字数を指定しても大丈夫です。
まとめ
以上、複数の文字列が区切り文字で結合されている場合、右から任意の区切り位置で切り取る方法を説明しました。
今回取り上げた課題例は正式な会社組織名の略称表示でした。
SUBSTITUTE関数は区切り位置を指定できるのですが、指定方法は「左から何番目か」のみです。そこで「右から何番目か」という指定を、区切り文字の出現回数を使って「左から何番目か」に変換しました。
関数を組み合わせて使う手順は少々複雑なので、3つの個別処理に分けて説明しました。
本記事が少しでも読者のExcel上達に役立てれば幸いです。(終わり)


コメント